
WARNING: If you are a recruiter or a hiring manager, this article contains personal opinions and social details about myself that should not be used to evaluate candidates. These data points can be found on Facebook (publically-facing, intended for social use) but not LinkedIn (employer-facing, intended for professional use).
Background
The other day, I decided to bulk connect to my fellow Northwestern students that are attending Kellogg’s MBA program – specifically my friends I know through my church. I am a Latter-day Saint (LDS, colloquially known as Mormon) as are several MBAs. After sending connection requests to 2-3 MBAs on LinkedIn, I was astounded to see other LDS MBAs come up in the “People Also Viewed” frame. I suspect that LinkedIn’s algorithm unwittingly determined that I was looking for LDS MBAs at Kellogg and fed me one profile after another.

I started to become curious to know, after I had connected with all the LDS MBAs, who would be the next most likely MBA profile? In other words, who is the most connected to Mormons Non-LDS MBA at Kellogg? Unfortunately though, once I connected with all the MBAs, the recommendations turned towards their former colleagues. This presented an interesting experiment and became my quest.
Methodology
My way to get to the bottom of this is pretty straight forward. I will see which Kellogg MBA is most connected to the LDS MBA candidates. To do this, I will need to scrape all of the MBAs’ connections. How do I know which MBA candidates are LDS? To be scientific, I used the profiles of members of the Kellogg’s LDSSA (LDS Student Association). Kellogg is a good test population because it is nearly a requirment for students to use LinkedIn.
Webscraping with R
Conducting webscraping in R is something I have wanted to try since I saw a co-worker of mine use RSelenium for a work project. It is one of those things that sounds really advanced and sexy. In fact, a former employer once paid $10,000 for a contractor to build a fairly basic webscrape in PHP. In reality, it was surprisingly simple thanks to Selenium. All it takes is a little knowledge of front-end (HTML, CSS, JavaScript), a little knowledge of R, the piecing together of a few outdate vignettes from the package creators, and some trial-and-error. About 95% of this scrape took me less than an hour… the last 5% took me another 2 hours of fiddling, optimizing and debugging.
I should note some of the ethics behind webscraping - some websites do not allow it for a variety of reasons. Some sites just to not like the traffic and LinkedIn generates revenue by selling access to their APIs (an easier, more efficient way to get the data than a webscrape). However, LinkedIn was recently ordered to allow webscrapes from 3rd parties. Here is the article. While there is little sites can do to stop you from scraping, the honorable thing is to check the site’s terms and conditions. And if APIs are free and available, use them instead of scraping. After scraping, I did notice that LinkedIn no longer allows me to view 2nd level connections. Not sure if this is LinkedIn just being wonky or if they do not appreciate my scrape (even though it have to allow it).
Getting Started with RSelenium
First, I tried to follow the RSelenium vignette here command-by-command. Then I realized that it detours into a Docker vignette here. This was confusing. Ultimately, the vignettes seem to be outdated because other commands exist in RSelenium which make starting way easier. I downloaded Docker, but I am not sure if that is necessary. The only commands you need to get started (once you have installed the RSelenium library) are:
# Libraries
library(RSelenium)
# Start browser control
rD <- rsDriver()
remDr <- rD$client

This should pop-up a Chrome browser with a little note “Chrome is being controlled by automated test software”. And sure enough, as R executes commands, you can watch the browser as if it is being controlled by a person. For good measure (and reasons I will explain later), I maximize the size of the browser window.
remDr$maxWindowSize() # Maximize browswer window
The vignette walks through the basic commands: navigation and interaction so check that out for an exhaustive list. For me to start, I need to navigate to www.LinkedIn.com and enter my username and password. Here is where a little HTML/CSS/JavaScript is handy. To interact with the page, you first need to find the “element” (to use HTML parlance). A quick way to do this is to right-click on the your element and select “Inspect.” This will bring up Chrome’s developer windows which are incredibly intimidating at first. Essentially, this is the code that makes the page look the way it does. You can hover over elements and Chrome will highlight the associated code.
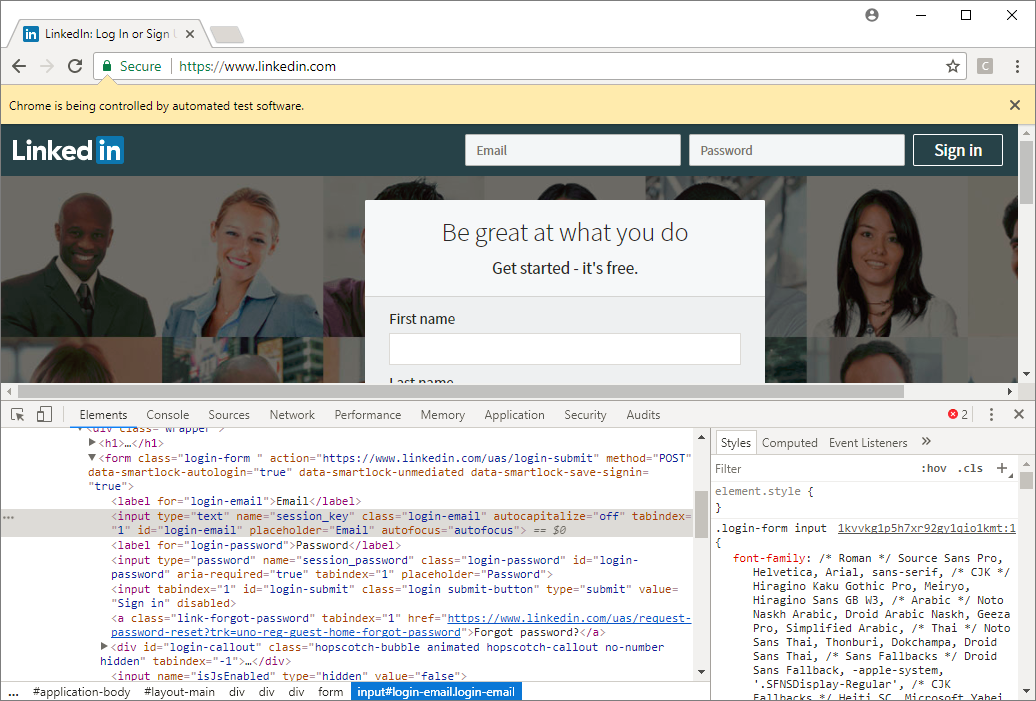
<input type="text" name="session_key" class="login-email" autocapitalize="off" tabindex="1" id="login-email" placeholder="Email" autofocus="autofocus">
It looks like this element is an input, which is good because we need to input our email. RSelenium gives several options to select the element, I think the most straightforward of which is using the id. This is the part that takes some trial-and-error. Once we select the element, we can interact with it by sending keys to it such as our email.
# Navigate to LinkedIn and Log In
remDr$navigate("https://www.linkedin.com/") # Navigate to login page
email_elem <- remDr$findElement(using = 'id', value = "login-email") # Find the email field
email_elem$sendKeysToElement(list("jeffrey.x.parker@gmail.com")) # Enter my email
pw_elem <- remDr$findElement(using = 'id', value = "login-password") # Find the password field
pw_elem$sendKeysToElement(list("************", key = "enter")) # Enter my password and press enter
Scraping
Now I am logged into LinkedIn. For the next steps, I found it best to make the clicks in person and write the steps out before writing them into code.
- Navigate to MBA’s profiles
- Click to see their connections
- Expand the options to see 3rd+ connections
LinkedIn can be quite finicky - this took me a while to figure out. Some elements do not load if they are not visible in the browser. This is why I maximized the browser window and also why I occasionally scroll to bottom of each page. Also LinkedIn pages take a while to load. So I peppered my code with delays to ensure I could access all the elements.
remDr$navigate("https://www.linkedin.com/in/ACoAAAnnocgBcHj3uRAXgAUq4GL7V_m2KzUDfA4") # 1. Navigate to one of my connections (this is my wife's profile)
see_connections_elem <- remDr$findElement('css', "[data-control-name= 'view_all_connections']")
see_connections_elem$clickElement() # 2. Click to see their connections
Sys.sleep(2)
third_connections_box <- remDr$findElement('css', "[title='3rd+']")
third_connections_box$clickElement() # 3. Expand the options to see 3rd+ connections
Only 10 connections appear on a page, but all of those connections maintain the same HTML/CSS element properties. So I can search and select all of them.
# Scrolling and Delaying
Sys.sleep(2)
webElem <- remDr$findElement("css", "body")
webElem$sendKeysToElement(list(key = "end"))
Sys.sleep(1)
webElem$sendKeysToElement(list(key = "end"))
# Finding all the `search_srp_result` elements and parsing out the href from each
connections <- remDr$findElements("css", "[data-control-name='search_srp_result']")
page_connections <- unlist(sapply(connections, function(x){x$getElementAttribute("href")}))
Now I need to saves those connections and click the “Next” button if it exists. This requires a while-loop and a TryCatch function - both of which are fairly advanced R functions. Note that I use tidyverse here to remove duplicates and for tibbles (instead of data frames). tidyverse is just my personal preference - I use this package in nearly every project.
# Libraries
library(tidyverse)
# Initialize Data Frame
all_connections <- tibble()
# Scrape connections, while clicking on the "next" element if it exists
element_exists <- TRUE
while(element_exists){
# Let the page load and scroll to the bottom of the page so we can see all the elements
Sys.sleep(2)
webElem <- remDr$findElement("css", "body")
webElem$sendKeysToElement(list(key = "end"))
Sys.sleep(1)
webElem$sendKeysToElement(list(key = "end"))
# Check to see if "next" exists
element_exists <- tryCatch({remDr$findElement('css', "[class='next']")$isElementDisplayed()[[1]]}
, error=function(e){FALSE}
, message = function(e){FALSE}
)
# If "Next" does not exist then scrape the page and break the while loop
if (element_exists==FALSE){
connections <- remDr$findElements("css", "[data-control-name='search_srp_result']")
page_connections <- tibble(MBA = MBAs[1], connection = unlist(sapply(connections, function(x){x$getElementAttribute("href")}))) %>%
distinct()
all_connections<- rbind(all_connections, page_connections)
break;
}
# If "Next" does exist, then scrape the page and click "Next"
connections <- remDr$findElements("css", "[data-control-name='search_srp_result']")
page_connections <- tibble(MBA = MBAs[1], connection = unlist(sapply(connections, function(x){x$getElementAttribute("href")}))) %>%
distinct()
all_connections<- rbind(all_connections, page_connections)
next_button <- remDr$findElement('css', "[class='next']")
next_button$clickElement()
}
This code will go through all the pages of connections and save their links. The last steps is to put it all together in a for-loop to go through all the MBA’s profiles. Also do NOT forget to turn off your controlled browser!
remDr$close()
rD$server$stop()
Results
Of the 11 LDS MBAs, 6 profiles were scraped, 2 profiles had privacy settings enabled so I was unable to see their connections and I am still pending connection for another 3 MBAs. The count of their connections varies between 500 and 1,000.
ggplot(all_connections) +
geom_bar(aes(x = MBA, y = ..count..)) +
xlab("MBA Profile") +
ylab("Count of Connections") +
ggtitle("Count of Connections for Each MBA Profile") +
theme(axis.text.x=element_blank())

Then I went through the profiles with the most connections in common. The top profiles included myself (of course), a career counseler from BYU and an LDS MBA attending Booth before I found my result.
all_connections %>%
count(connection) %>%
arrange(desc(n))
The honorary title of “The Most Mormon Non-LDS MBA at Kellog” goes to this candidate! Naturally, I am obscuring personal information for his/her privacy. Turns out this candidate attended Stanford as an undergraduate where he/she was good friends with a LDS MBA candidate. According to the LDS MBAs, this candidate is good friends with all the LDS MBAs in part because he/she has kids and is the Kellogg Kids Club (many of the LDS MBAs also have kids as well). Diving a little deeper, I found out that this candidate was actually raised LDS in California, but his/her family went inactive while he/she was a teenager. My wife actually predicted this would happen. I actually find this really interesting that the person has maintained such close ties.
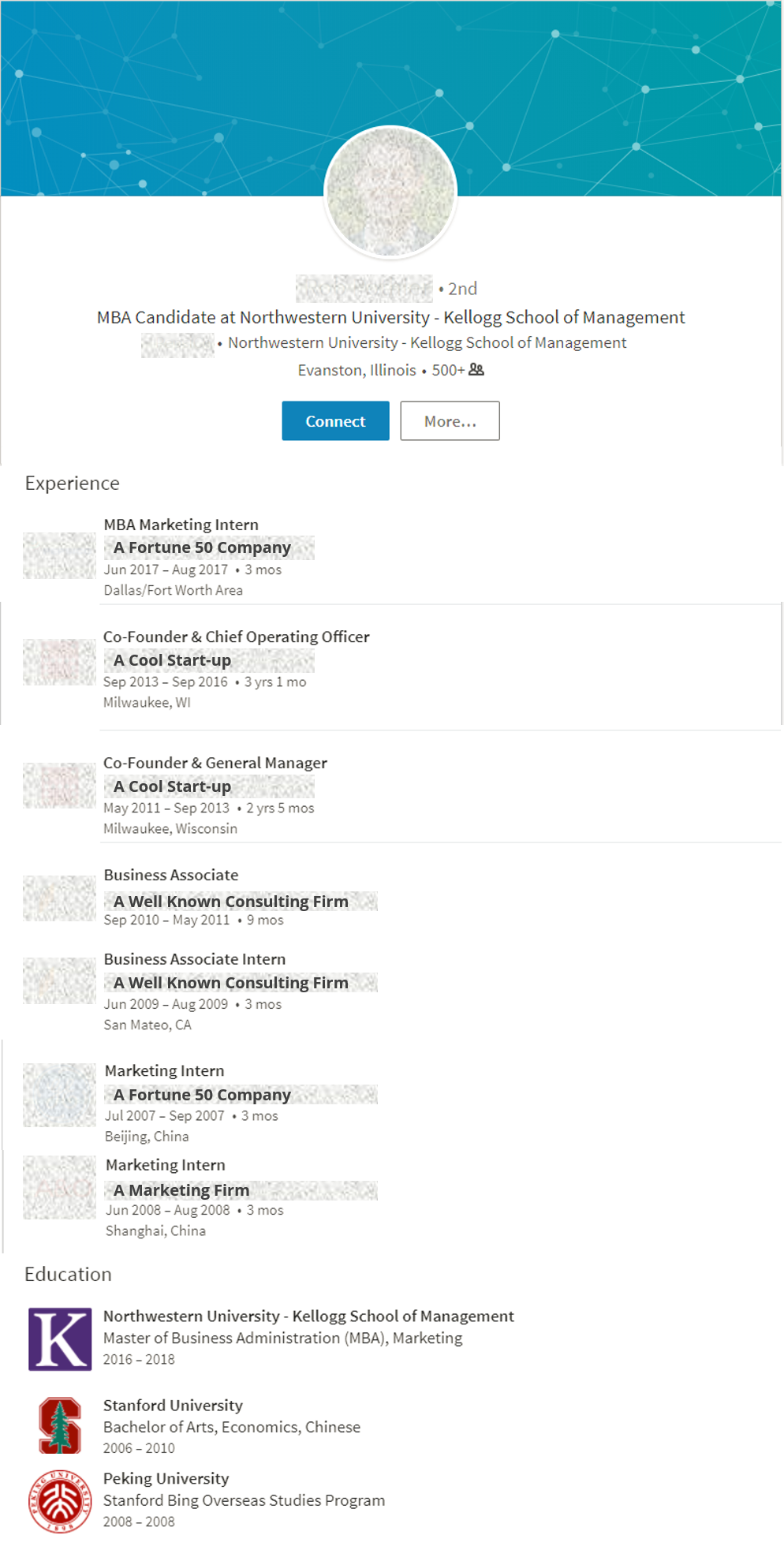
Feel free to let me know what you think in the comments.